http://www.metamorphosite.com/one-way-hash-encryption-sha1-d....
The biggest risk I see with this is how torrents are affected:
https://en.wikipedia.org/wiki/Torrent_poisoning
There's also a problem with git, but I don't see it being that as susceptible as torrents:
In their example they've created two PDFs with the same SHA-1. Could I replace the blob in a git repo with the "bad" version of a file if it matches the SHA-1?
Is there a rough calculation in terms of today's $$$ cost to implement the attack?
Pretty impressive, though. And worrying, because if Google can do it, you know that state-level actors have been probably doing it for some time now (if only by throwing even more computing power at the problem).
* DHT/torrent hashes - A group of malicious peers could serve malware for a given hash.
* Git - A commit may be replaced by another without affecting the following commits.
* PGP/GPG -- Any old keys still in use. (New keys do not use SHA1.)
* Distribution software checksum. SHA1 is the most common digest provided (even MD5 for many).
Edit: Yes, I understand this is a collision attack. But yes, it's still a attack vector as 2 same blocks can be generated now, with one published, widely deployed (torrent/git), and then replaced at a later date.
No need to wait. The option to reject SHA-1 certificates on Firefox is `security.pki.sha1_enforcement_level` with value `1`.
https://blog.mozilla.org/security/2016/01/06/man-in-the-midd...
Other configs worth doing:
`security.ssl.treat_unsafe_negotiation_as_broken` to `true` and `security.ssl.require_safe_negotiation` to `true` also. Refusing insecure algorithms (`security.ssl3.<alg>`) might also be smart.
Is this correct?
Release the clean one and let it spread for a day or two. Then join the torrent, but spread the malware-hosting version. Checksums would all check out, other users would be reporting that it's the real thing, but now you've got 1000 people purposely downloading ransomware from you- and sharing it with others.
Apparently it costs around $100,000 to compute the collisions, but so what? If I've got 10,000 installing my 1BTC-to-unlock ransomware, I'll get a return on investment.
This will mess up torrent sharing websites in a hurry.
Edit: some people have pointed out some totally legitimate potential flaws in this idea. And they're probably right, those may sink the entire scheme. But keep in mind that this is one idea off the top of my head, and I'm not any security expert. There's plenty of actors out there who have more reasons and time to think up scarier ideas.
The reality is, we need to very quickly stop trusting SHA1 for anything. And a lot of software is not ready to make that change overnight.
https://www.schneier.com/blog/archives/2012/10/when_will_we_...
Pretty close in his estimation.
wasn't SHA-1 introduced in the 90's?
Actually a serious question. How do we communicate something like this to the general public?
Like a NURBS based sudoku multi-hash...
We're at the "First collision found" stage, where the programmer reaction is "Gather around a co-worker's computer, comparing the colliding inputs and running the hash function on them", and the non-expert reaction is "Explain why a simple collision attack is still useless, it's really the second pre-image attack that counts".
See https://lists.linuxfoundation.org/pipermail/bitcoin-dev/2013... and https://bitcoinchain.com/block_explorer/address/37k7toV1Nv4D...
B = 3,116,899,000,000,000,000
G = 9,223,372,036,854,775,808
Every three seconds the Bitcoin mining network brute-forces the same amount of hashes as Google did to perform this attack. Of course, the brute-force approach will always take longer than a strategic approach; this comment is only meant to put into perspective the sheer number of hashes calculated.
https://www.facebook.com/notes/alex-stamos/the-sha-1-sunset/...
https://blog.twitter.com/2015/sunsetting-sha-1
https://blog.cloudflare.com/sha-1-deprecation-no-browser-lef...
I think Microsoft tried to do it too early on, but eventually agreed to a more aggressive timeline.
That part from the original article seems to be missing something?
and it's super effective: The possibility of false positives can be neglected as the probability is smaller than 2^-90.
It's also interesting that this attack is from the same author that detected that Flame (the nation-state virus) was signed using an unknown collision algorithm on MD5 (cited in the shattered paper introduction).
What this means is for all of you [developers], is to start new projects without SHA1 and plan on migrating old ones (if it's totally necessary, normally don't unless you use SHA1 for passwords).
A Great resource for those who still don't know how or what hash to use, is paragonie: https://paragonie.com/blog/2016/02/how-safely-store-password...
It says "Upload any file to test if they are part of a collision attack."
When I upload either of their two sample collision documents, it says they are "Safe."
That is mathematically impossible when reducing an N bit string to an M bit string, where N > M.
All hashes have collisions; it's just how hard are they to find.
$ls -l sha*.pdf
-rw-r--r--@ 1 amichal staff 422435 Feb 23 10:01 shattered-1.pdf
-rw-r--r--@ 1 amichal staff 422435 Feb 23 10:14 shattered-2.pdf
$shasum -a 1 sha*.pdf
38762cf7f55934b34d179ae6a4c80cadccbb7f0a shattered-1.pdf
38762cf7f55934b34d179ae6a4c80cadccbb7f0a shattered-2.pdf
$shasum -a 256 sha*.pdf
2bb787a73e37352f92383abe7e2902936d1059ad9f1ba6daaa9c1e58ee6970d0 shattered-1.pdf
d4488775d29bdef7993367d541064dbdda50d383f89f0aa13a6ff2e0894ba5ff shattered-2.pdf
$md5 sha*.pdf
MD5 (shattered-1.pdf) = ee4aa52b139d925f8d8884402b0a750c
MD5 (shattered-2.pdf) = 5bd9d8cabc46041579a311230539b8d1https://github.com/vegard/sha1-sat
and his Master Thesis, whose quality is approaching a PhD thesis is here:
https://www.duo.uio.no/bitstream/handle/10852/34912/thesis-o...
Note that they also only mention MiniSat as a footnote, which is pretty bad. The relevant paper is at
http://minisat.se/downloads/MiniSat.pdf
All of these are great reads. Highly recommended.
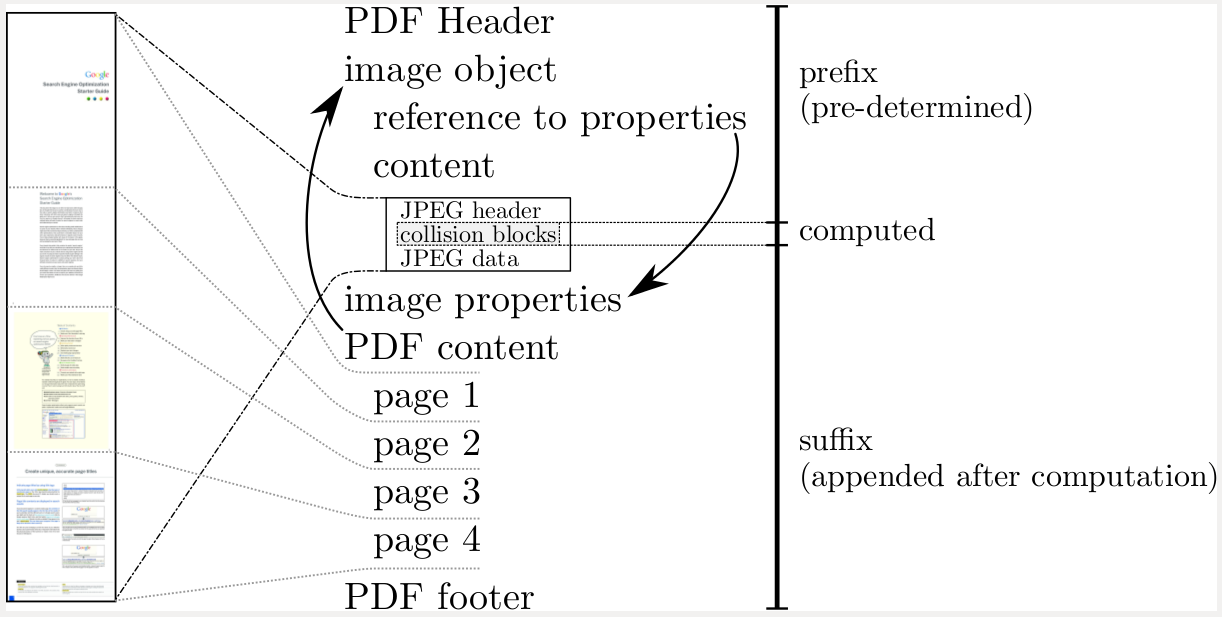
> A picture is worth a thousand words, so here it is.
> http://shattered.io/static/pdf_format.png
This picture is meaningless to me. Can someone explain what's going on?
I wonder why they did not use the 2^52 operation attack that Schneier noted in 2009?
https://www.schneier.com/blog/archives/2009/06/ever_better_c...
I know the attack isn't practical today, but the writing is on the wall.
Collision attack: find two documents with the same hash. That's what was done here.
Second-preimage attack: given a document, find a second document with the same hash.
First-preimage attack: given an arbitrary hash, find a document with that hash.
These are in order of increasing severity. A collision attack is the least severe, but it's still very serious. You can't use a collision to compromise existing certificates, but you can use them to compromise future certificates because you can get a signature on one document that is also valid for a different document. Collision attacks are also stepping stones to pre-image attacks.
UPDATE: some people are raising the possibility of hashes where some values have 1 or 0 preimages, which makes second and first preimage attacks formally impossible. Yes, such hashes are possible (in fact trivial) to construct, but they are not cryptographically secure. One of the requirements for a cryptographically secure hash is that all possible hash values are (more or less) equally likely.
Basically, each PDF contains a single large (421,385-byte) JPG image, followed by a few PDF commands to display the JPG. The collision lives entirely in the JPG data - the PDF format is merely incidental here. Extracting out the two images shows two JPG files with different contents (but different SHA-1 hashes since the necessary prefix is missing). Each PDF consists of a common prefix (which contains the PDF header, JPG stream descriptor and some JPG headers), and a common suffix (containing image data and PDF display commands).
The header of each JPG contains a comment field, aligned such that the 16-bit length value of the field lies in the collision zone. Thus, when the collision is generated, one of the PDFs will have a longer comment field than the other. After that, they concatenate two complete JPG image streams with different image content - File 1 sees the first image stream and File 2 sees the second image stream. This is achieved by using misalignment of the comment fields to cause the first image stream to appear as a comment in File 2 (more specifically, as a sequence of comments, in order to avoid overflowing the 16-bit comment length field). Since JPGs terminate at the end-of-file (FFD9) marker, the second image stream isn't even examined in File 1 (whereas that marker is just inside a comment in File 2).
tl;dr: the two "PDFs" are just wrappers around JPGs, which each contain two independent image streams, switched by way of a variable-length comment field.
Give me the sha1 and md5, rather than one or the other. Am I wrong in thinking even if one or both are broken individually, having both broken for the same data is an order of magnitude more complex?
Huh? It's been around a lot longer than 10 years.
And this, my friends, is why the big players (google, Amazon, etc) will win at the cloud offering game. When the instances are not purchased they can be used extensively internally.
I don't expect one overnight. For one, as noted, this is a collision attack, one which took a large scale of power to achieve. In light of that, I don't think the integrity of git repos is in immediate danger. So I don't think it'd be an immediate concern of the the Git devs.
Secondly, wouldn't moving to SHA-2 or SHA-3 be a compatibility-breaking change? I'd think that would be painful to deal with, especially the larger the code base, or the more activity it sees. Linux itself would be a worst-case scenario in that regard. But, it can be pulled off for Linux, then I'd think any other code base should be achievable.
It looks like the did the same thing or something similar in 2^57.5 SHA1 calculations back then versus 2^63 SHA1 calculations this time.
My understanding of crypto concepts is very limited, but isn't this inaccurate? Hash functions do not compress anything.
They have an image too which says "<big number> SHA-1 compressions performed".
Seems weird to see basic mistakes in a research disclosure.
As for what I think in general about it: I'm not concerned, worried, or even scared about the effects. If anything, inelegance of brute-force aside, I think there's something very beautiful and awe-inspiring in this discovery, like solving a puzzle or maths conjecture that has remained unsolved for many years.
I remember when I first heard about MD5 and hash functions in general, and thinking "it's completely deterministic. The operations don't look like they would be irreversible. There's just so many of them. It's only a matter of time before someone figures it out." Then, years later, it happened. It's an interesting feeling, especially since I used to crack softwares' registration key schemes which often resembled hash functions, and "reversing" the algorithms (basically a preimage attack) was simply a matter of time and careful thought.
There's still no practical preimage for MD5, but given enough time and interest... although I will vaguely guess that finding SHA-256 collisions probably has a higher priority to those interested.
BTW quine relay is impressive: https://github.com/mame/quine-relay
Why? Was it in anticipation of this attack specifically?
{kind=link}
{kind=link}
Comments: